Chapter 6 Mixed Integer Optimization
Up until this point, we have always assumed that variables could take on fractional (or non-integer) values. In other words, they were continuous variables. Sometimes the values conveniently turned out to be integer-valued, in other cases, we would brush off the non-integer values of the results.
Allowing for integer values opens up many more important areas of applications as we will see. Let’s look at two numerical examples. The first shows a case where integrality makes little difference, the second where it has a major impact.
Unfortunately, there is no such thing as a free lunch-adding and integrality can make problems much more computationally demanding. We will go through an example of how many optimization routines do integer optimization to demonstrate why it can be more difficult algorithmically even if looks trivially easy from the perspective of the change in the omprfunction.
6.1 Example of Minor Integrality Impact
Let’s revisit the earlier example of producing drones with one additional hour in assembly as we did in Chapter 4. As a reminder, the LP is the same three variable case we have been using with a change of 901 instead of 900 for the second constraint’s right hand side.
\[ \begin{split} \begin{aligned} \text{Max } & 7\cdot Ants +12 \cdot Bats +5\cdot Cats \\ \text{s.t.: } & 1\cdot Ants + 4\cdot Bats +2\cdot Cats \leq 800 \\ & 3\cdot Ants + 6\cdot Bats +2\cdot Cats \leq \textcolor{red}{901} \\ & 2\cdot Ants + 2\cdot Bats +1\cdot Cats \leq 480 \\ & 2\cdot Ants + 10\cdot Bats +2\cdot Cats \leq 1200 \\ & Ants, Bats, Cats \geq 0 \end{aligned} \end{split} \]
We use the following implementation.
model1 <- MIPModel() |>
add_variable(Ants, type = "continuous", lb = 0) |>
add_variable(Bats, type = "continuous", lb = 0) |>
add_variable(Cats, type = "continuous", lb = 0) |>
set_objective(7*Ants + 12*Bats + 5*Cats,"max") |>
add_constraint(1*Ants + 4*Bats + 2*Cats<=800) |> # machining
add_constraint(3*Ants + 6*Bats + 2*Cats<=901) |> # assembly
add_constraint(2*Ants + 2*Bats + 1*Cats<=480) |> # testing
add_constraint(2*Ants + 10*Bats + 2*Cats<=1200) # sensors
result1 <- solve_model(model1, with_ROI(solver="glpk"))
inc_as_res <- cbind (result1$objective_value,
t(result1$solution))
colnames(inc_as_res)<-c("Profit", "Ants", "Bats", "Cats")
kbl (inc_as_res, digits=6, booktabs=T,
caption="Production Plan with Continuous Variables") |>
kable_styling(latex_options = "hold_position")| Profit | Ants | Bats | Cats |
|---|---|---|---|
| 2227.25 | 50.5 | 0 | 374.75 |
In this case, the fractional value of Cats would be only somewhat concerning. We wouldn’t actually ship an 80% complete Cat drone to a customer-at least I hope not. The difference between 374 and 375 is relatively small over a month of production. This is a difference of much less than 1% and none of the numbers specified in the model appear to be reported to more than two significant digits or this level of precision. The result is that we could specify the answer as 374.8 and be satisfied that while it is our actual best guess or might reflect a chair half finished for the next month, it isn’t a major concern.
For the sake of illustration, let’s show how we would modify the model to be integers. If we had wanted to modify the problem to force the amount of each item to be produced to be an integer value, we can modify our formulation and the implementation with only a few small changes.
In the formulation, we can replace the non-negativity requirement with a restriction that the variables are drawn from the set of non-negative integers.
\[ \begin{split} \begin{aligned} \text{Max } & 7\cdot Ants +12 \cdot Bats +5\cdot Cats \\ \text{s.t.: } & 1\cdot Ants + 4\cdot Bats +2\cdot Cats \leq 800 \\ & 3\cdot Ants + 6\cdot Bats +2\cdot Cats \leq 901\\ & 2\cdot Ants + 2\cdot Bats +1\cdot Cats \leq 480 \\ & 2\cdot Ants + 10\cdot Bats +2\cdot Cats \leq 1200 \\ & Ants, \; Bats, \; Cats \; \textcolor{red} { \in \{0,1,2,3, \ldots \} } \end{aligned} \end{split} \]
The ompr implementation has a similar, straightforward change. In the declaration of variables (add_variable function), we simply set the type to be integer rather than continuous. Since nothing else is changing in the model, we can simply re-add the variables to redefine them from being continuous to be integer.
model1 <- add_variable(model1, Ants, type = "integer", lb = 0)
model1 <- add_variable(model1, Bats, type = "integer", lb = 0)
model1 <- add_variable(model1, Cats, type = "integer", lb = 0)Let’s confirm that the implemented model is of the form desired.
model1## Mixed integer linear optimization problem
## Variables:
## Continuous: 0
## Integer: 3
## Binary: 0
## Model sense: maximize
## Constraints: 4We can see that it now has three integer variables replacing the variables of the same name that were continuous so let’s move on to solving it and comparing our results.
result1 <- solve_model(model1, with_ROI(solver="glpk"))| Profit | Ants | Bats | Cats | |
|---|---|---|---|---|
| Continuous | 2227.25 | 50.5 | 0 | 374.75 |
| Integer | 2227.00 | 51.0 | 0 | 374.00 |
Notice that in this case, there was a small adjustment to the production plan and a small decrease to the optimal objective function value. This is not always the case, sometimes the result can be unchanged. In other cases, it may be changed in a very large way. In still others, the problem may in fact even become infeasible.
6.2 Example of Major Integality Impact
Let’s take a look at another example. Acme makes two products, let’s refer to them as product 1 and 2. Product 1 generates a profit of $2000 per product, requires three liters of surfactant for cleaning, and eight kilograms of high grade steel.
In contrast, each unit of Product 2 produced generates a higher profit of $3000 per product, requires eight liters of surfactant, and three kilograms of high grade steel. Acme has 31 liters of surfactant and 26 kilograms of high grade steel.
Only completed products are sellable, what should be Acme’s production plan?
Formulating the optimization problem is similar to our earliest production planning problems. Let’s define \(x_1\) to be the amount of product 1 to produce and \(x_2\) to be the amount of product 2 to produce.
\[ \begin{split} \begin{aligned} \text{Max } & 2 x_1 + 3 x_2 \\ \text{s.t. } & 3 x_1 + 9 x_2 \leq 31 & \text{[Surfactant]}\\ & 8 x_1 + 3 x_2 \leq 26 & \text{[Steel]}\\ & x_1, \; x_2 \in \{0,1,2,3,...\} \end{aligned} \end{split} \] At first glance, this looks the same as our earlier drone eample but the last constraint cannot be solved directly strictly using linear programming. It is instead referred to as an integer linear program or ILP.
Again, we could try solving it with and without the imposition of the integrality constraint.
LPRmod <- MIPModel() |>
add_variable(Vx1, type = "continuous", lb = 0) |>
add_variable(Vx2, type = "continuous", lb = 0) |>
set_objective(2*Vx1 + 3*Vx2, "max") |>
add_constraint(3.0*Vx1 + 9.0*Vx2 <= 31) |> # Surfactant
add_constraint(8.0*Vx1 + 3.0*Vx2 <= 26) # Steel
LPSolR <- solve_model(LPRmod, with_ROI(solver = "glpk"))
obj_val <- objective_value(LPSolR)
x1 <- get_solution (LPSolR, 'Vx1')
x2 <- get_solution (LPSolR, 'Vx2')
acme_res_lp <- cbind(x1,x2,obj_val)
colnames(acme_res_lp) <- list("x1", "x2", "Profit")
rownames(acme_res_lp) <- "LP Solution"All we need to do is repeat the same process with changing the variable type to integer instead of continuous.
IPmod <- add_variable(LPRmod, Vx1, type = "integer", lb = 0) |>
add_variable(Vx2, type = "integer", lb = 0)
IPSolR <- solve_model (IPmod, with_ROI(solver = "glpk"))
obj_val <- objective_value(IPSolR)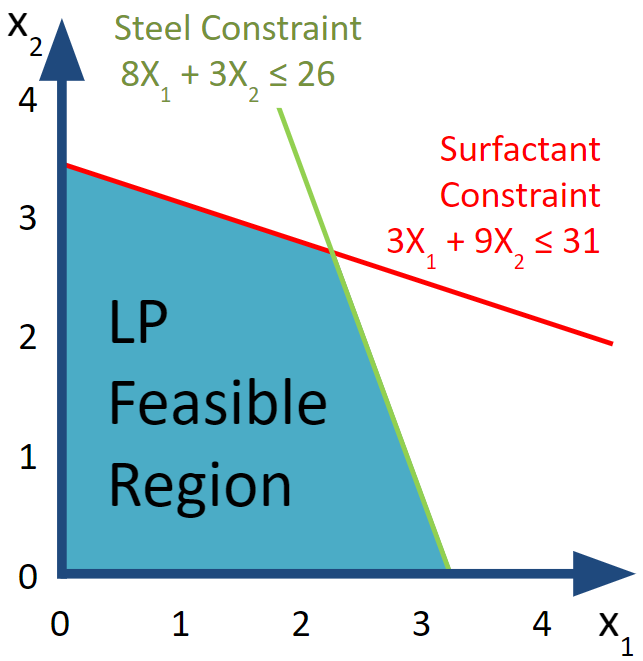
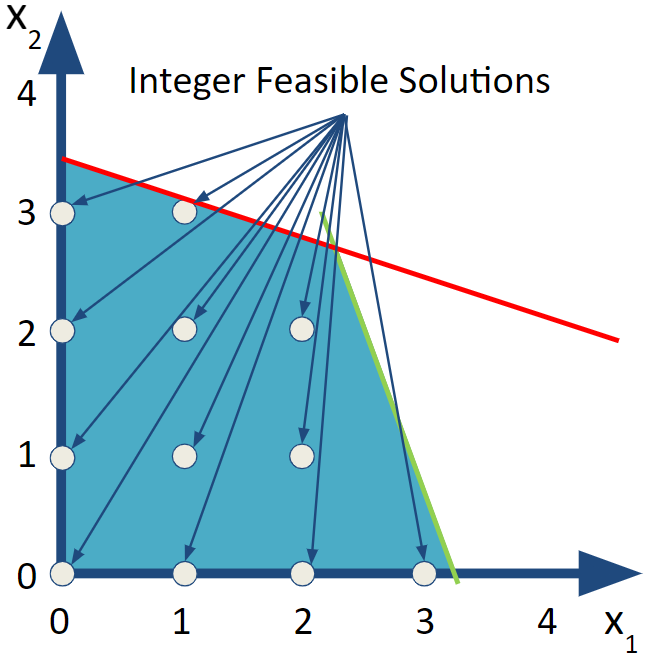
FIGURE 6.1: LP Region and 12 IP Feasible Solutions
x1 <- get_solution (IPSolR, 'Vx1')
x2 <- get_solution (IPSolR, 'Vx2')
acme_res_ip <- cbind(x1,x2,obj_val)
colnames(acme_res_ip) <- list("x1", "x2", "Profit")
rownames(acme_res_ip) <- "IP Solution"
kbl (rbind(acme_res_lp,acme_res_ip), booktabs=T, digits=3,
caption="Production Plan-Continuous vs. Integer") |>
kable_styling(latex_options = "hold_position")| x1 | x2 | Profit | |
|---|---|---|---|
| LP Solution | 2.238 | 2.698 | 12.571 |
| IP Solution | 1.000 | 3.000 | 11.000 |
Simply rounding down did not yield an optimal solution. Notice that production of product 1 went down while product 2 went up. The net impact was a profit reduction of almost 10%.
6.3 The Branch and Bound Algorithm
The simplicity of making the change in the model from continuous to integer variables hides or understates the complexity of what needs to be done computationally to solve the optimization problem. This small change can have major impacts on the computational effort needed to solve a problem. Solving linear programs with tens of thousands of continuous variables is very quick and easy computationally. Changing those same variables to general integers can make it very difficult. Why is this the case?
At its core, the basic problem is that the Simplex method and linear programming solves a system of equations and unknowns (or variables). It is trivial to solve one equation with one unknown such as \(5x=7\). It is only slightly harder to solve a system of two equations and two unknowns. Doing three equations and three unknowns requires some careful algebra but is not hard. In general, solving n equations and n unknowns is readily solvable. On the other hand, none of this algebraic work of solving for unknown variables can require that the variables take on integer values. Even with only one equation (say \(C\cdot x=12\)), one unknown variable (\(x\)), and one constant (\(C\)), x will only be integer for certain combinations of numbers in the above equation. It gets even less likely to have an all integer solution as the number of equations and unknowns increase.
Another way to visualize integer solutions for general systems of inequalities is to think of the case with two equations and two unknowns (x and y). Finding a solution is the same as finding where two lines intersect in two dimensional space. The odds of getting lucky and having the two lines intersect at an integer solution is small. Even if we limit ourselves to x and y ranging from 0 to 10, this means that there are \(11^2=121\) possible integer valued points in this space such as (0,0), (0,3), and (10,10). In contrast, the set of all points, including non-integers, in this region includes all of the above points as well as (0,0.347) and (4.712, 7.891) among infinitely more. The result is that if you think of this as a target shooting, the probability of finding an integer solution by blind luck is \(\frac{121}{\infty}\approx 0\).
What we need is an algorithm around the Simplex method to accomplish this. A basic and common and approach often used for solving integer variable linear programming problems is called Branch and Bound. We start with a solution that has presumably continuous valued variables. We then branch (create subproblems) off of this result for variables that have fractional values but should be integers and add bounds (additional constraints) to rule out the fractional value of that variable.
Given the importance of integer programming and the impact on solving speed, we’ll demonstrate the process by showing the steps graphically and in R.
6.3.1 The LP Relaxation
To solve this using branch and bound, we relax the integrality requirements and solve what is called the LP Relaxation. To do this, we simply remove the integrality requirement.
\[ \begin{split} \begin{aligned} \text{Max } & 2 x_1 + 3 x_2 \\ \text{s.t. } & 3 x_1 + 9 x_2 \leq 31 & \text{[Surfactant]}\\ & 8 x_1 + 3 x_2 \leq 26 & \text{[Steel]}\\ & x_1, \; x_2 \geq 0 \end{aligned} \end{split} \]
Unlike requiring the variables to be integer valued, this is a problem that we can solve using linear programming so let’s go ahead do it! Well, we already did so let’s just review the results for what is now called the LP Relaxation because we are relaxing the integrality requirements.
kbl (acme_res_lp, booktabs=T, digits=3,
caption="Acme's Production Plan based on the LP Relaxation") |>
kable_styling(latex_options = "hold_position")| x1 | x2 | Profit | |
|---|---|---|---|
| LP Solution | 2.238 | 2.698 | 12.571 |
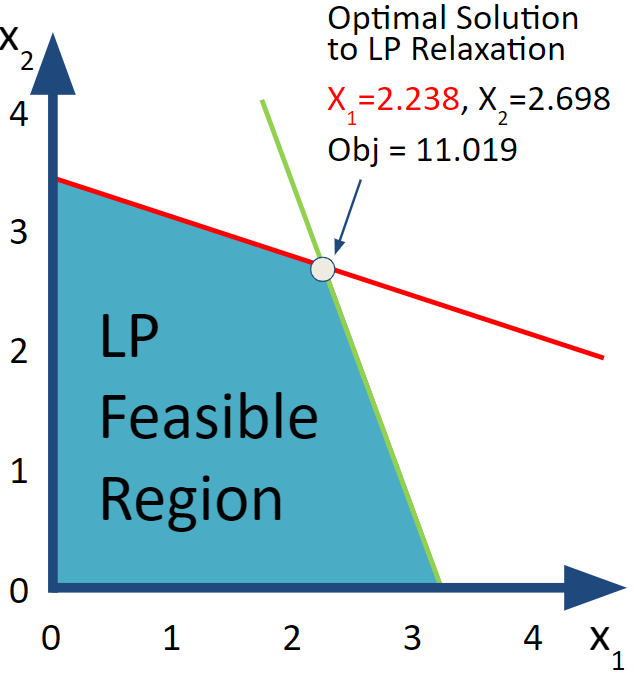
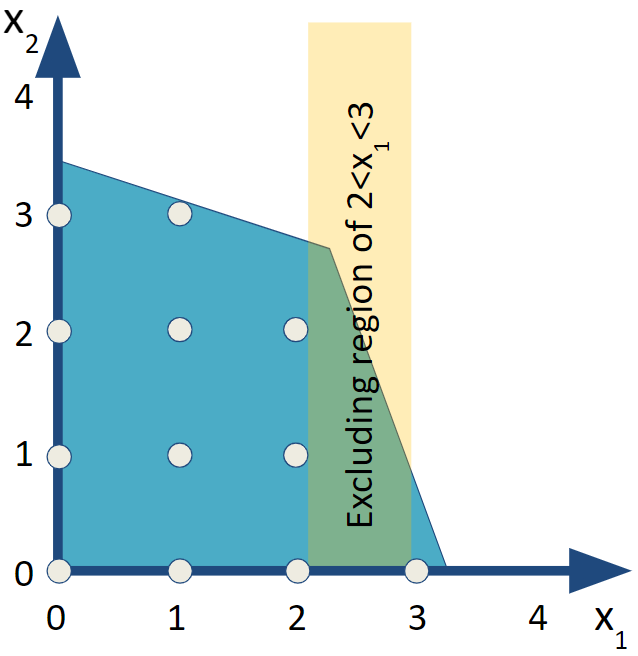
FIGURE 6.2: LP Relaxation
6.3.2 Subproblem I
Alas, this production plan from the LP Relaxation is not feasible from the perspective of the original integer problem because it produces 2.238 of product 1 and 2.698 of product 2. If both of these variables had been integer we could have declared victory and been satisfied that we had easily (luckily?) found the optimal solution to the original integer programming problem so quickly.
Instead, we will need to proceed with the branch and bound process. Since both of the variables in the LP relaxation have fractional values, we need to start by choosing which variable to use for branching first. Algorithmic researchers would focus on how to best pick a branch but for our purposes to improve solution speed but it doesn’t really matter for illustration so let’s arbitrarily choose to branch on \(x_1\).
For the branch and bound algorithm, we want to include two subproblems that exclude the illegal value of \(x_1=2.238\) as well as everything else between 2 and 3. We say that we are branching on \(x_1\) to create two subproblems. The first subproblem (I) has an added constraint of \(x_1\le 2.0\) and the other subproblem (II) has an added constraint of \(x_1\ge 3.0\).
\[ \begin{split} \begin{aligned} \text{Max } & 2 x_1 + 3 x_2 \\ \text{subject to } & 3 x_1 + 9 x_2 \leq 31 \\ & 8 x_1 + 3 x_2 \leq 26 \\ & \textcolor{red} {x_1 \leq 2.0} &text{[Bound for Subproblem I]}\\ & x_1, \; x_2 \geq 0 \\ \end{aligned} \end{split} \tag{6.1} \]
Since this is just a bound on the decision variable, we can implement it by just modifying the LP Relaxation’s model LPRmod that we created earlier by redefining the \(x_1\) variable (Vx1).
LPSubI <- add_variable(LPRmod, Vx1, type = "continuous",
lb = 0, ub=2.0)
LPSubI <- solve_model(LPSubI, with_ROI(solver = "glpk"))
obj_val <- objective_value(LPSubI)
x1 <- get_solution (LPSubI, 'Vx1')
x2 <- get_solution (LPSubI, 'Vx2')
LPSubI_res <- cbind(x1,x2,obj_val)| x1 | x2 | obj_val |
|---|---|---|
| 2 | 2.778 | 12.333 |
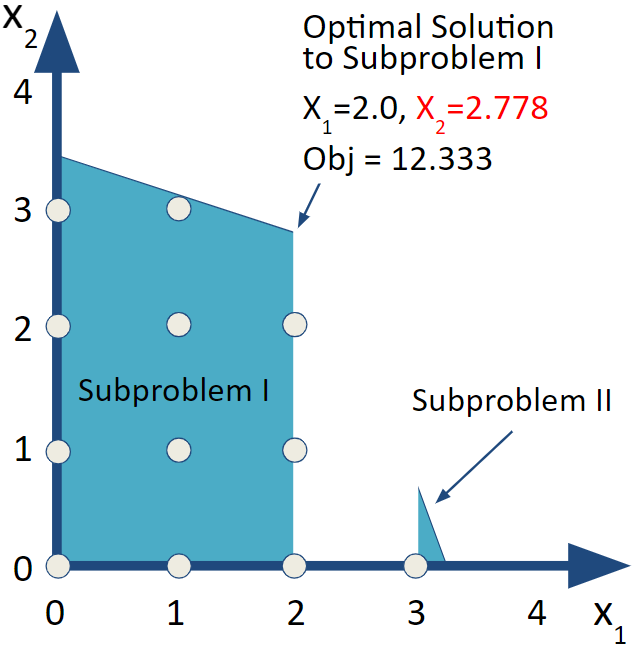
FIGURE 6.3: Subproblem I
Looking over the results, we now get an integer value for \(x_1\) but not for \(x_2\). We repeat the same process by creating subproblems from Subproblem I by branching off of \(x_2\).
6.3.3 Subproblem III
Choosing which subproblem to examine next is one of the areas that large scale integer programming software and algorithms specialize in and provide options. One way to think of it is to focus on searching down a branch and bound tree deeply or to search across the breadth of the tree. For this example, let’s go deep which means jumping ahead to Subproblem III but we’ll return to Subproblem II later.
Since \(x_2\) is now a non-integer solution, we will create branches with bounds (or constraints) on \(x_2\) in the same manner as before. Subproblem III has an added constraint of \(x_2 \le2.0\) and Subproblem IV has \(x_2 \ge3.0\).
To simplify the implementation, I can simply change the upper and lower bounds on variables rather than adding separate variables.
LPSubIII <- LPRmod |>
add_variable(Vx1, type = "continuous", lb = 0, ub = 2) |>
add_variable(Vx2, type = "continuous", lb = 0, ub = 2) |>
solve_model(with_ROI(solver = "glpk"))| x1 | x2 | obj_val |
|---|---|---|
| 2 | 2 | 10 |
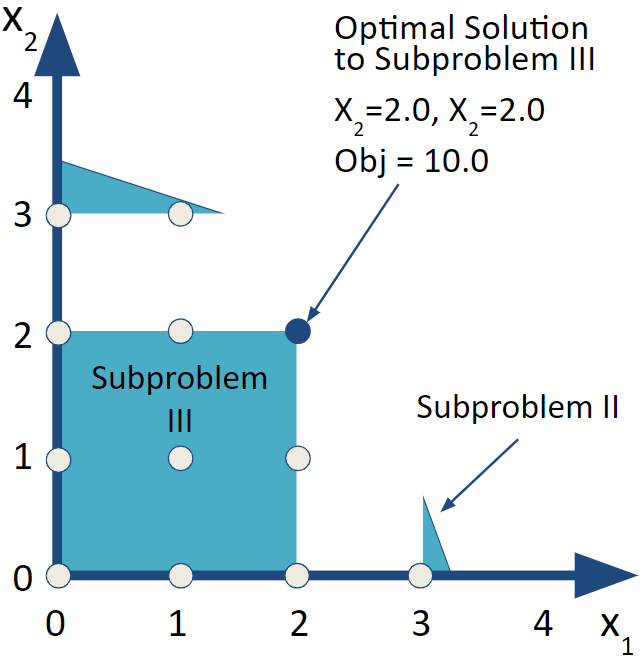
FIGURE 6.4: Subproblem III-An IP Feasible Solution
This results in integer values for both \(x_1\) and \(x_2\) so it is feasible with respect to integrality in addition to of course satisfying the production constraints. It does generate less profit than the LP relaxation. While it is feasible, it doesn’t prove that it is optimal though. We need to explore the other potential branches.
6.3.4 Subproblem IV
Next, let’s look at Subproblem IV. This problem adds the bound of \(x_2\ge3.0\) to Subproblem I. Notice that in the MIPModel implementation the variable for \(x_1\) (Vx1) has an upperbound of 2, (ub=2) in order to implement the bounding constraint for Subproblem I and the lower bound on \(x_2\) of 3 in the variable declarations. Notice from the earlier graphical examples, there is no feasible region (blue area) that has \(x_2\geq3\). By visual inspection, we expect this to be an infeasible subproblem but let’s confirm it.
LPSubIV <- add_variable(LPRmod, Vx1, type = "continuous",
lb = 0, ub = 2)
LPSubIV <- add_variable(LPSubIV, Vx2, type = "continuous",lb = 3)
LPSubIV <- solve_model(LPSubIV, with_ROI(solver = "glpk"))| x1 | x2 | obj_val |
|---|---|---|
| 1.333 | 3 | 11.667 |
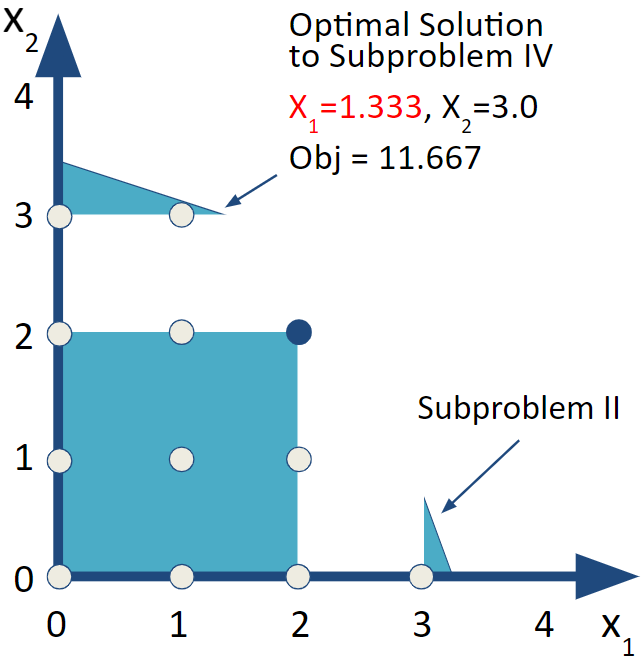
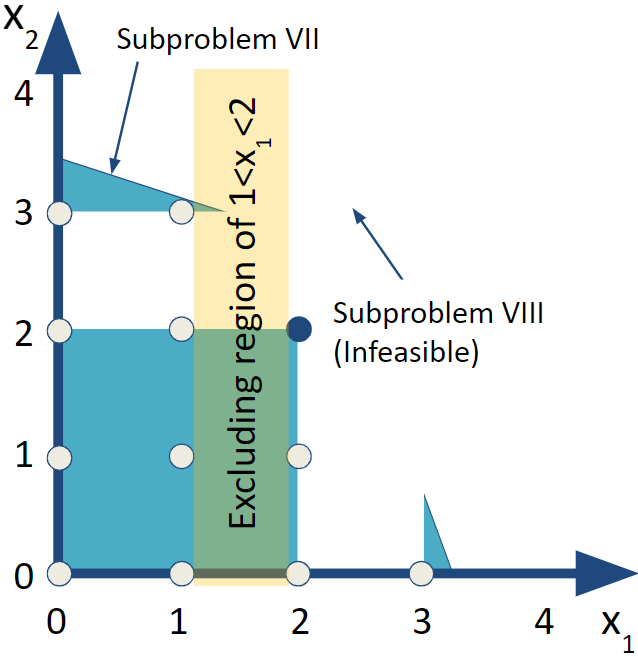
FIGURE 6.5: Subproblem IV
While \(x_2\) is now integer valued, \(x_1=1.333\) so it is no longer integer valued. We need to repeat the process of branching on \(x_1\) again for Subproblems V and VI.
6.3.5 Subproblem V
For Subproblem V, use a constraint of \(x_1\leq 1\). We’ll continue with adjusting the bounds of the variables to do the branch and bound.
LPSubV <- add_variable(LPRmod, Vx1, type = "continuous",
lb = 0, ub = 1)
LPSubV <- add_variable(LPSubV, Vx2, type = "continuous",lb = 3)
LPSubV <- solve_model(LPSubV, with_ROI(solver = "glpk"))| x1 | x2 | obj_val | |
|---|---|---|---|
| 1 | 3.111 | 11.333 |
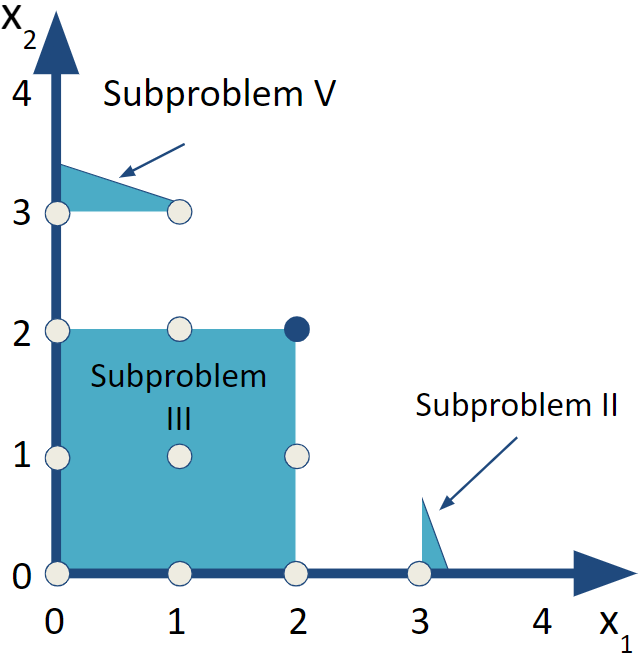
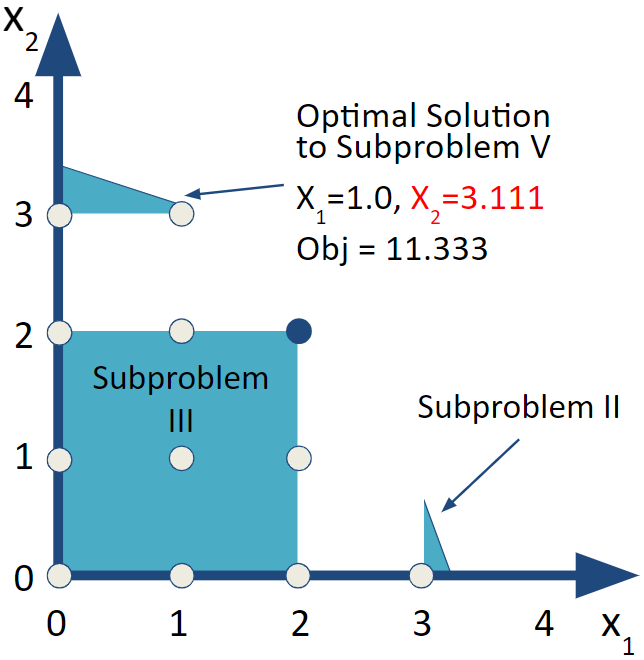
FIGURE 6.6: Subproblems V and VI
Unfortunately the solution to Subproblem V now has \(x_2=3.111\) so we will need to repeat this branch and bound for Subproblems VII and VIII. Before we do that, let’s consider Subproblem VI.
6.3.6 Subproblem VI
In this case, we our retaining our previous bounds from Subproblems I and IV while adding a bound for \(x_1\). The result is that our bounds on \(x_1\) is \(2\leq x_1\leq 2\) or in other words, \(x_1=2\) while \(x_2\geq3\). A careful look at the previous figure suggest there is no feasible solution in this situation but let’s solve the corresponding LP to confirm this.
LPSubVI <- add_variable(LPRmod, Vx1, type = "continuous",
lb = 2, ub = 2)
LPSubVI <- add_variable(LPSubVI, Vx2, type = "continuous",
lb = 3)
LPSubVI <- solve_model(LPSubVI, with_ROI(solver = "glpk"))
LPSubVI$status## [1] "infeasible"obj_val <- objective_value(LPSubVI )
x1 <- get_solution (LPSubVI , 'Vx1')
x2 <- get_solution (LPSubVI , 'Vx2')
LPSubVI_res <- cbind(x1,x2,obj_val)| x1 | x2 | obj_val | |
|---|---|---|---|
| 2 | 3 | 13 |
The ompr status value of this solved LP indicates that Subproblem VI is infeasible. It still returned values that were used when it determined that the problem was infeasible which is why it gave the results in the previous table. From here on out, it is a good reminder to check the status. Note that it can be used as an in-line evaluated expression to simply say was it feasible or not? Yes, it was infeasible.
6.3.7 Subproblem VII
Let’s return to branching off of Subproblem V to examine Subproblems VII and VIII.
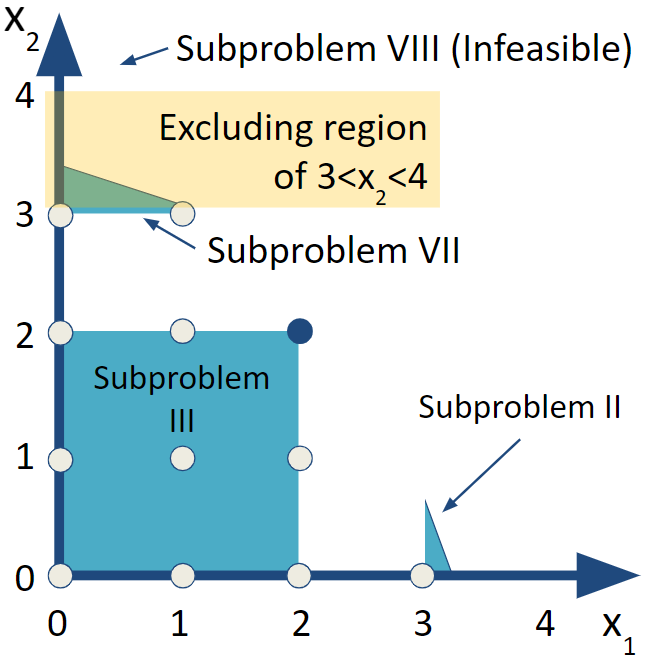
FIGURE 6.7: Subproblem VI
LPSubVII <- add_variable(LPRmod, Vx1, type = "continuous",
lb = 0, ub = 1)
LPSubVII <- add_variable(LPSubVII, Vx2, type = "continuous",
lb=0, ub=3)
LPSubVII <- solve_model(LPSubVII, with_ROI(solver = "glpk"))| x1 | x2 | obj_val | |
|---|---|---|---|
| 1 | 3 | 11 |
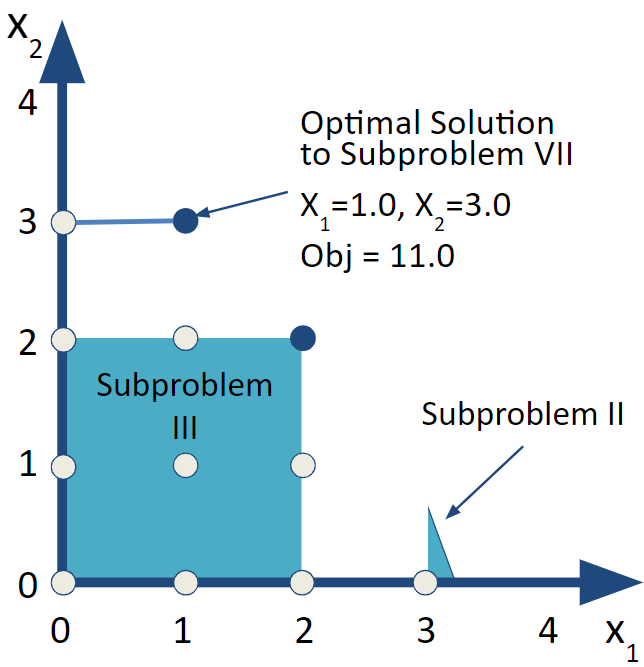
FIGURE 6.8: Subproblem VII
This solution is all integer valued and the objective function is better than our previous integer valued solution. The result is that we have a new candidate optimal solution. Since there are still branches to explore, we can’t declare victory.
6.3.8 Subproblem VIII
Setting a lower bound of \(x_2\geq 4\) makes the problem infeasible. We can see from the drawings of the feasible region that the feasible region does not extend to that height at all regardless of what \(x_1\) is. We can confirm by solving Subproblem VIII though since we don’t generally have the luxury of looking at the feasible region. Again, the results table highlights that care must be taken to not give credence to values returned from an infeasible solution.
LPSubVIII <- add_variable(LPRmod, Vx1, type = "continuous", lb = 1,)
LPSubVIII <- add_variable(LPSubVIII, Vx2, type = "continuous", lb = 4)
LPSubVIII <- solve_model(LPSubVIII, with_ROI(solver = "glpk"))
LPSubVIII$status## [1] "infeasible"| x1 | x2 | obj_val | |
|---|---|---|---|
| 1 | 4 | 14 |
6.3.9 Subproblem II
Now, we have searched down all branches or subproblems descending from Subproblem I so we can return to Subproblem II. Let’s go back and do that problem. We do that by simply adding one new bound to the LP Relaxation. That is \(x_1\geq 3.0\).
LPSubII <- LPRmod |>
add_variable(Vx1, type = "continuous", lb = 3) |>
add_variable(Vx2, type = "continuous", lb = 0) |>
solve_model(with_ROI(solver = "glpk"))
cat("Status of Subproblem II:",LPSubII$status)## Status of Subproblem II: optimalrownames(LPSubII_res) <- ""| x1 | x2 | obj_val | |
|---|---|---|---|
| Vx1 | 3 | 0.667 | 8 |
FIGURE 6.9: Subproblems VI and VII
At this point, our first reaction may be to breathe deeply and do the same branch and bound off of \(x_2\). On the other hand, if we step back and take note that the objective function value is 10.0, while optimal for Subproblem II, it is less than what we found from a feasible, fully integer-valued solution to Subproblem III and the even better Subproblem VII. Given that adding constraints can’t improve an objective function value, we can safely trim all branches below Subproblem II.
Given that we no longer have any branches to explore, we can declare that we have found the optimal solution. The optimal solution can now be definitively stated to be what we found from Subproblem VII.
| x1 | x2 | obj_val | |
|---|---|---|---|
| 1 | 3 | 11 |
Before this, we could only say that it was feasible solution and candidate to be optimal since no better integer feasible solution had been found.
Let’s summarize the results of the series of LPs solved.
| x1 | x2 | Profit | |
|---|---|---|---|
| LP Relaxation | 2.238 | 2.698 | 12.571 |
| Subproblem I | 2.000 | 2.778 | 12.333 |
| Subproblem III | 2.000 | 2.000 | 10.000 |
| Subproblem IV | 1.333 | 3.000 | 11.667 |
| Subproblem V | 1.000 | 3.111 | 11.333 |
| Subproblem VI |
|
|
Infeasible |
| Subproblem VII | 1.000 | 3.000 | 11.000 |
| Subproblem VIII |
|
|
Infeasible |
| Subproblem II | 3.000 | 0.667 | 8.000 |
The Branch and Bound process is often characterized as a tree. Each subproblem is a circle and represents a separate linear program with its objective function value and decision variable values. The arcs or branches connecting to a new node show the added constraint.
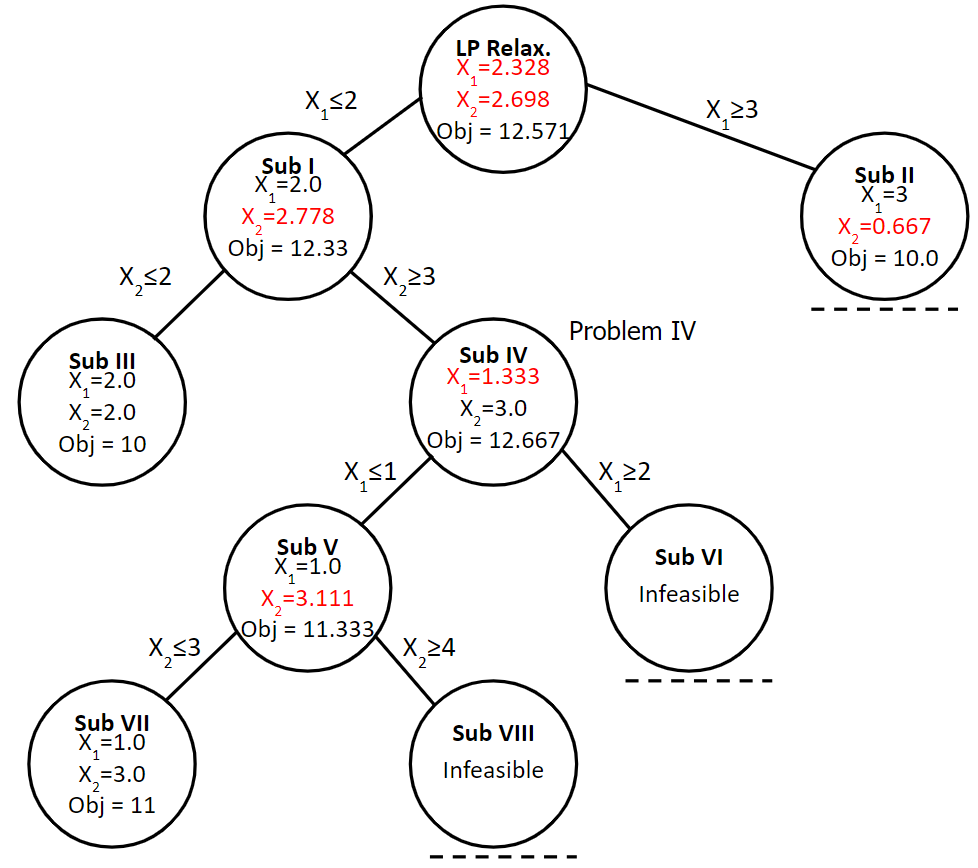
FIGURE 6.10: Branch and Bound Tree
6.4 Computational Complexity
As for computational complexity, this was a small problem with only two integer variables but it still required solving the LP Relaxation and four separate LP subproblems for a total of five linear programs in all. As the number of variables and constraints increases, so do the number of LPs needed to typically find a solution using branch and bound. Small and medium size problems can generally be solved quickly but worst case scenarios have a combinatorial explosion.
6.4.1 Full Enumeration
Another approach to integer programming is full enumeration which means listing out all possible solutions and then determining if that solution is feasible and if so, what the objective function value is. Alas, this can result in a combinatorial explosion. For example, if a problem has 1,000 non-negative integer variables each of which can range from zero to nine, full enumeration would require listing \(10^{1000}\) possible solutions. This is far larger than the number of grains of sand on Earth (~\(10^{19}\)) or the number of stars in the universe (~\(10^{19}\)). In fact this is much larger than the number of atoms in the universe (~\(10^{80}\)). Needless to say explicit enumeration for large problems is not an option.
The Branch and Bound algorithm has the benefit that it will find the optimal solution. Sometimes it will find it quickly, other times it may take a very long time.
Worst case scenarios for Branch and Bound may approach that of full enumeration but in practice performs much better. A variety of sophisticated algorithmic extensions have been added by researchers over the years but solving large scale integer programming problems can still be quite difficult.
One option to deal with long solving times is to set early termination conditions such as running for a certain number of seconds. If it is terminated early, it may report the best feasible solution found so far and a precise bound as to how much better an as yet unfound solution might be based on the best remaining open branch. This difference between the best feasible solution found so far and the theoretically possible best solution to be found gives a gap that an analyst can set. This acceptable gap is sometimes referred to as a suboptimality tolerance factor. In other words, what percentage of suboptimality is the analyst willing to accept for getting a solution more quickly. For example, a suboptimality tolerance factor of 10% would tell the software to terminate the branch and bound algorithm if a feasible solution is found and it is certain that regardless of how much more time is spent solving, it is impossible to improve upon this solution by more than 10%.
In practice, even small suboptimality tolerance factors like 1% can allow big problems to be solved quickly and are often well within the margin of error for model data. In other cases, organizations may be interested in finding any feasible solution to large, vexing problems.
Note that our Acme example only specified two digits of accuracy for resource usage and may have only one digit of accuracy for profitability per product.
Note that in our earlier example, if we had a wide enough suboptimality tolerance, say 30% and followed the branch for \(x_1\ge3.0\) first rather than \(x_1\le2.0\), we might have terminated with a suboptimal solution.
6.5 Binary Variables and Logical Relations
Binary variables are a special case of general integer variables. Rather than variables taking on values such as 46 and 973, acceptable values are limited to just 0 and 1. This greatly reduces the possible search space for branch and bound since you know that in any branch, you will never branch on a single variable more than once. On the other hand, with a large number of variables, the search space can still be very large. If the previous case with 1000 variables were binary, a full enumeration list would rely on a list of \(2^{1000}\) or one followed by about 300 zeros) possible solutions. While better than the case of integers, it is still vastly more than the number of atoms in the universe.
The important thing is is that binary variables give us a lot of rich opportunities to model complex, real world situations.
Examples include assigning people to projects, go-no go decisions on projects, and much more.
Let’s explore the impact of binary restrictions with another example. The world famous semiconductor company, Outtel has a choice of five major R&D projects:
- Develop processor architecture for autonomous vehicles
- Next generation microprocessor architecture
- Next generation process technology
- New fabrication facility
- New interconnect technology
The key data is described as follows. NPV is Net Present Value of the project factoring in costs. Inv is the capital expenditures or investment required for each project. The company has $40 Billion in capital available to fund a portfolio of projects. Let’s set up the data as matrices in R.
I <- matrix(c(12,24,20,8, 16), ncol=1,
dimnames=list(LETTERS[1:5],"Inv"))
N <- matrix(c(2.0, 3.6, 3.2, 1.6, 2.8), ncol=1,
dimnames=list(LETTERS[1:5],"NPV"))
kbl (cbind(I,N), booktabs=T,
caption="Data for the Outtel Example")| Inv | NPV | |
|---|---|---|
| A | 12 | 2.0 |
| B | 24 | 3.6 |
| C | 20 | 3.2 |
| D | 8 | 1.6 |
| E | 16 | 2.8 |
These projects all carry their own expenses and engineering support. There are limits to both the capital investment and engineering resources available. To start, consider all of these project to be independent.
Exercise 6.1 (Create and Solve Model) Formulate and solve a basic, naive model that allows projects to repeated and partially completed. Implement and solve your model. (Hint: You don’t need binary variables yet.) What is the optimal decision? Is this result surprising? Does this make sense in terms of the application?
Exercise 6.2 (No Project is Repeated) Now, let’s explore one aspect of moving towards binary variables. What constraint or constraints are needed to ensure no project is done more than once while allowing partial projects to still be funded and incur both proportionate costs and benefits. How does this solution compare to that of above?
Exercise 6.3 (No Partial Projects) What change is needed to prevent partial funding of projects. How does this solution compare to that of above? Can you envision a situation where it might make sense to have partially funded projects? Could this be similar to corporate joint ventures where investments and benefits are shared across multiple entities?
Now that you have binary constraints, let’s explore the impact of logical restrictions with a series of separate scenarios. In each of these cases, make sure that you implement the relationship as a linear relationship. This means that you cannot use a function such as an “If-then,” “OR,” “Exclusive OR,” or other relationship. Furthermore, you can’t multiply variables together or divide variables into variables.
Let’s assume that projects A and B require the focused effort of Outtel’s top chip architects and Outtel has decided therefore that it is not possible to do both projects.
Therefore, they want to ensure that at most one of the two projects can be pursued. What needs to be added to enforce this situation?
Let’s start with a truth table summarizing the interaction between projects (variable values) and the “Top Chip Architects” relationship.
Project A \(y_A\) |
Project B \(y_B\) |
Violates “Top Chip Architects” Relationship |
|---|---|---|
| 0 | 0 | No |
| 0 | 1 | No |
| 1 | 0 | No |
| 1 | 1 | Yes |
Now we need to create a constraint that blocks the situations that violate the relationship (\(y_A=y_B=1\) ) but allows the other situations to be unblocked. Recall that you want to have a linear constraint or constraints that would be added to the model. In this case, we can use \(y_A+y_B\leq1\). It is a good exercise to check this relationship against the truth table.
Note that we cannot use \(y_{A}\cdot y_{B}=0\) because it is a nonlinear constraint when we multiply two variables together. Sometimes trial and error is needed to verify that a constraint enforces the needed situation. In these case, it can be helpful to draw up a truth table with values for the associated variables and see whether the satisfies the requirement.
In each of the following sections create a linear relationship that models this situation.
Exercise 6.4 (Interconnects Need Something to Connect) Instead of the constraint on chip architects, let’s consider the situation of the interconnect technology. Assume that project E on interconnect technology would only provide strong benefit if a new architecture is also developed. In other words, E can only be done if A or B is done. Note that if both A and B are done, E will certainly have a use!
Exercise 6.5 (Manufacturing) Outtel knows that staying aggressive in manufacturing is important in this competitive industry but that it is too risky to do too much at once from manufacturing perspective. The result is that Outtel want to ensure that exactly one major manufacturing initiative (C or D) must be done. In other words, project C or project D must be done but not both.
Exercise 6.6 (Solving Each Case) Solve for the base case and then show the results of just each constraint at once. Combine the results into a single, well-formatted table. Discuss the results.
Exercise 6.7 (Full Enumeration) When projects can be neither partially funded nor repeated, how many candidate solutions would there be by full enumeration? List them.
6.6 Fixed Charge Models
Fixed charge models are a special case of integer programming models where situations where product cost has a fixed cost component and a marginal (per unit) cost component. A common example of this is when a machine must be setup before any production can occur.
6.6.1 Fixed Charge Example-Introduction
In our example, we need to connect or link the two decision variables of how much to produce and whether to produce for each of the products.5
Let’s explore an example of a fixed charge problem. Widget Inc. is re-evaluating their product production mix. As the plant manager, you are responsible for determining what products the company should manufacture. Since the company is leasing equipment, there are setup costs for each product. You need to determine the mix that will maximize profit for the company.
The profit for each Widget is shown below, as well as the setup costs (if you decide to produce any of that that Widget). The materials you have sourced allow you to only produce each Widget up to its capacity.
| Product | Profit | Setup Cost | Capacity |
|---|---|---|---|
| Widget 1 | $15 | $1000 | 500 |
| Widget 2 | $10 | $1500 | 1000 |
| Widget 3 | $25 | $2000 | 750 |
To produce each Widget, the hours required at each step of the manufacturing process are shown below. Also shown are the availability (in hours) of the equipment at each step.
| Production | Widget 1 | Widget 2 | Widget 3 | Available |
|---|---|---|---|---|
| Pre-process | 2 | 1 | 3 | 1000 |
| Machining | 1 | 5 | 2 | 2000 |
| Assembly | 2 | 1 | 1 | 1000 |
| Quality Assurance | 3 | 2 | 1 | 1500 |
In order to develop our optimization model, we determine the objective function (goal), decision variables (decisions) and constraints (limitations).
Objective Function: Maximize net profit
Decision Variables:
- \(W_1\) = Number of Widget 1 to produce
- \(W_2\) = Number of Widget 2 to produce
- \(W_3\) = Number of Widget 3 to produce
- \(Y_1\) = 1 if you choose to produce Widget 1; 0 otherwise
- \(Y_2\) = 1 if you choose to produce Widget 2; 0 otherwise
- \(Y_3\) = 1 if you choose to produce Widget 3; 0 otherwise
Constraints:
- Using no more than 1000 hours of Pre-process
- Using no more than 2000 hours of Machining
- Using no more than 1000 hours of Assembly
- Using no more than 1500 hours of Quality Assurance
- Producing no more than 500 of Widget 1
- Producing no more than 1000 of Widget 2
- Producing no more than 750 of Widget 3
We can then write this as the following formulation.
\[ \begin{split} \begin{aligned} \text{Max } & 15W_1+10W_2+25W_3 - 1000Y_1 - 1500Y_2 - 2000Y_3 \\ \text{s.t.: } & 2W_1+1W_2+3W_3 \leq 1000 \\ & 1W_1+5W_2+2W_3 \leq 2000 \\ & 2W_1+1W_2+1W_3 \leq 1000 \\ & 3W_1+2W_2+1W_3 \leq 1500 \\ & W_1 \leq 500 \\ & W_2 \leq 1000 \\ & W_3 \leq 750 \\ & W_1, \; W_2, \; W_3 \geq 0 \\ & Y_1, \; Y_2, \; Y_3 \; \in \{0,1\} \\ \end{aligned} \end{split} \tag{6.2} \]
Let’s examine the results if we run this model.
For fixed charge problems, we need to link our Widget production volume to our decision on whether or not we produce the Widget (and its associated setup costs). We do this what is called the “Big M” method and the aptly named linking constraint.
fc_base_model <- MIPModel() |>
add_variable(Vw1, type="integer", lb=0, ub=500) |>
add_variable(Vw2, type="integer", lb=0, ub=1000) |>
add_variable(Vw3, type="integer", lb=0, ub=750) |>
add_variable(Vy1, type="binary") |>
# Binary Decision for Widget 1 Setup
add_variable(Vy2, type = "binary") |>
# Binary Decision for Widget 2 Setup
add_variable(Vy3, type = "binary") |>
# Binary Decision for Widget 3 Setup
set_objective(15*Vw1 + 10*Vw2 + 25*Vw3
- 1000*Vy1 - 1500*Vy2 - 2000*Vy3,
"max") |>
add_constraint(2*Vw1 + 1*Vw2 + 3*Vw3 <= 1000) |> # Pre-process
add_constraint(1*Vw1 + 5*Vw2 + 2*Vw3 <= 2000) |> # Machining
add_constraint(2*Vw1 + 1*Vw2 + 1*Vw3 <= 1000) |> # Assembly
add_constraint(3*Vw1 + 2*Vw2 + 1*Vw3 <= 1500) # Quality
fc_base_res <- solve_model(fc_base_model,
with_ROI(solver = "glpk"))
fc_base_res## Status: optimal
## Objective value: 8845Our analysis found an optimal solution with a profit of 8845. At first glance, this may look good but let’s examine the results in more detail.
fc_base_summary <-
cbind(fc_base_res$objective_value,
t(as.matrix(fc_base_res$solution)))
colnames(fc_base_summary)<-
c("Net Profit", "$w_1$","$w_2$","$w_3$",
"$y_1$","$y_2$","$y_3$")
kbl (fc_base_summary, booktabs=T, escape=F,
caption = "Base Case Solution for Fixed Charge Problem") |>
kable_styling(latex_options = "hold_position") |>
footnote ("Note that no setups are incurred.")| Net Profit | \(w_1\) | \(w_2\) | \(w_3\) | \(y_1\) | \(y_2\) | \(y_3\) |
|---|---|---|---|---|---|---|
| 8845 | 0 | 307 | 231 | 0 | 0 | 0 |
| Note: | ||||||
| Note that no setups are incurred. |
We are producing a mix two products \(w_2\) and \(w_3\) are positive but \(y_2=y_3=0\). This is a nice, very high profit situation because we are not paying for the production setups. It may not be surprising that the optimization model chooses to avoid “paying” the fixed charge for production. This is a “penalty” in the objective function. What we need is a way of connecting the amount to produce of a widget and the decision to produce any of that widget. In reality, it would be necessary to pay the setup costs for the second and third products (\(1500+2500\)) bringing the total profit down to 5345. Since the model is not factoring in the production setup cost, perhaps a higher net profit could be found if we could directly account this in our product offerings.
What we need is a way to connect, associate, or dare I say “link” each production decision, \(w\), with its setup decision, \(y\). In fact, this connection is called a linking constraint and is quite common in mixed integer programming problems.
Let’s return to the idea of the truth table - let’s focus on widget 2.
| Amount to Produce \(w_2\) | Decision to Produce \(y_2\) | Interpretation of situation |
|---|---|---|
| 0 | 0 | OK - choosing to do nothing |
| 0 | 1 | OK - perhaps not a “smart” option but not impossible or unheard of |
| 1 | 0 | impossible - can’t produce even a single sellable product without doing a setup |
| 1 | 1 | OK |
| 42 | 0 | impossible |
| 42 | 1 | OK |
For illustration purposes, I pick three different widget 2 production values (\(w_2\)). The value of \(w_2=0\) means that we aren’t actually producing anything. In this case, it doesn’t matter whether we do a setup (\(y_2=1\)) or not (\(y_2=0\)). Some people might be offended by a situation of not producing anything but paying for a setup. The objective function will discourage this situation from happening so as to avoid paying for a setup but it is possible that there might be other relationships between products. In addition, we are all probably familiar with organizations that have invested in a product, only to never put it in service. We don’t need to make the constraint enforce smart operations.
To demonstrate the relationship between the decisions for widget 2, it is also helpful to look at the small volume case of producing just 1 product (\(w_2=1\) ). The key situation here is to ensure that if we even make a single product, must not allow the optimization model to avoid doing a setup. Along the way, it is good to make sure that the relationship allows the solution of \(w_2=1\) and \(y_2=1\) to be considered feasible.
Lastly, I like to include a larger production volume to ensure that the constraint is properly enforcing this relationship. The value, 42, is just an arbitrary one and could be any other moderately large value.
6.6.2 Linking Constraints with “Big M”
The linking constraint as the following: \(w_1 \leq M \cdot y_1\) The value \(M\) is a big value that is so large that it does not prematurely limit the production for widget 1. Whatever value of \(M\) is used, \(w_1\) can never exceed that value.
Our linking constraints force our new values to be 0 or 1. If \(w_1 > 0\), then this constraint forces the associated \(y_1\) to be equal to 1. If \(w_1 = 0\), then this constraint allows \(y_1\) to be either 0 or 1. However, our objective function will cause Solver to avoid paying a setup by setting \(y_1=0\).
It might be tempting to select a very large number such as a billion \(10^{10}\) but picking excessively large numbers, can result in poor computational performance. As we’ve discussed large, real-world optimization problems are hard enough, let’s not make it any harder. Albert Einstein once said “A model should be as simple as possible, but no simpler.” Essentially, a value for M should be as small as possible, but no smaller.
Since \(M\) serves to impose an upper bound on \(w_1\), this might suggest how we can use this information to pick an appropriate value for M and that we can do so for each product separately, using a separate value \(M_i\) for each widget.
Let’s examine the constraints for the production plan in the situation gives all resources to the production of Widget 1 and nothing to Widget 2 and Widget 3.
More formally, using the non-negative lower bounds on widget production, we can set \(w_2=w_3 = 0\) and substitute into the constraints of the optimization model. The constraints now look like the following:
\[ \begin{split} \begin{aligned} 2 \cdot w_1+1 \cdot 0+3 \cdot 0 \leq 1000 \\ 1 \cdot w_1+5 \cdot 0+2 \cdot 0 \leq 2000 \\ 2 \cdot w_1+1 \cdot 0+1 \cdot 0 \leq 1000 \\ 3 \cdot w_1+2 \cdot 0+1 \cdot 0 \leq 1500 \\ w_1 \leq 500 \\ 0 \leq 1000 \\ 0 \leq 750 \\ \end{aligned} \end{split} \tag{6.3} \]
This can be further simplified as the following.
\[ \begin{split} \begin{aligned} 2 \cdot w_1 \leq 1000 \\ 1 \cdot w_1 \leq 2000 \\ 2 \cdot w_1 \leq 1000 \\ 3 \cdot w_1 \leq 1500 \\ w_1 \leq 500 \\ \end{aligned} \end{split} \tag{6.4} \]
It can be further simplified as the following:
\[ \begin{split} \begin{aligned} w_1 \leq \frac{1000}{2} = 500 \\ w_1 \leq 2000 \\ w_1 \leq \frac{1000}{2} = 500 \\ w_1 \leq \frac{1500}{3} = 500 \\ w_1 \leq 500 \\ \end{aligned} \end{split} \tag{6.5} \]
Since all constraints need to be satisfied, we can represent this to mean that Widget 1 manufacturing could never be higher than the smallest (most restrictive) of these constraints.
Therefore, \[w_1 \leq min \{ \frac{1000}{2}, \frac{2000}{1}, \frac{1000}{2}, \frac{1500}{3}, 500 \}\]
or \[w_1 \leq min \{ 500, 2000, 500, 500, 500 \} = 500\] Therefore, we know that Widget 1 production can never exceed 500 units regardless of the amount of other Widgets (\(w_2\) and \(w_3\)) produced. We can then safely set the Big M value for Widget 1 to be 500. In other words, \(M_1=500\).
We can follow the same process for setting Big M values for widget 2. We start by setting \(w_1=w_3 = 0\). We know that \(w_2\) must be no larger than the most restrict constraint. I’ll skip rewriting the constraints and jump a little ahead.
\[W_2 \leq min \{ \frac{1000}{1}, \frac{2000}{5}, \frac{1000}{1}, \frac{1500}{2}, 1000 \}=400\]
Therefore, we can safely use a Big M value for \(w_2\) of \(M_2=400\).
Again we can follow the same process for \(w_3\) to find a small Big M value.
\[w_3 \leq min \{ \frac{1000}{3}, \frac{2000}{2}, \frac{1000}{1}, \frac{1500}{1}, 750 \}=333.33\] Since the Big M value is setting a lower bound, in this way, we can round up from 333.33 to 334. Our updated model with “Big M”:
\[ \begin{split} \begin{aligned} \text{Max } & 15w_1+10w_2+25w_3 - 1000y_1 - 1500y_2 - 2000y_3 \\ \text{s.t.: } & 2w_1+1w_2+3w_3 \leq 1000 \\ & 1w_1+5w_2+2w_3 \leq 2000 \\ & 2w_1+1w_2+1w_3 \leq 1000 \\ & 3w_1+2w_2+1w_3 \leq 1500 \\ & w_1 \leq 500 \\ & w_2 \leq 1000 \\ & w_3 \leq 750 \\ & \textcolor{red}{w_1 - 500y_1 \leq 0} \\ & \textcolor{red}{w_2 - 400y_2 \leq 0} \\ & \textcolor{red}{w_3 - 334y_3 \leq 0} \\ & w_1, w_2, w_3 \geq 0 \\ & y_1, y_2, y_3 \in \{0,1\} \\ \end{aligned} \end{split} \tag{6.6} \]
We could optionally delete the production capacity such as \(w_1 \leq 500\) as they are now redundant constraints because the fixed charge constraints also reflect these upper limits on production capacity.
6.6.3 Fixed Charge Implementation
Given that we have already created a model without the Big M constraints, we can simply add the constraints to the model. We’ll skip the piping operator and just add the constraint directly to the previous model, fc_base_model.
fc_bigM_model <- add_constraint(fc_base_model,
Vw1 - 500*Vy1 <= 0) |>
# W1's Big M linking constraint
add_constraint(Vw2 - 400*Vy2 <= 0) |>
# W2's Big M linking constraint
add_constraint(Vw3 - 334*Vy3 <= 0)
# W3's Big M linking constraint
fc_bigM_res <- solve_model(fc_bigM_model,
with_ROI(solver = "glpk"))
fc_bigM_res## Status: optimal
## Objective value: 6500Our model was able to find an optimal solution with an objective value of 6500. Our optimal production plan is shown below. As we can see, our model returned a production plan with only one model of widget being produced.
Interesting—the objective function value has gone down significantly. Let’s look this over in more detail and compare it to the results that we had when we avoided paying for setups.
| Net Profit | \(w_1\) | \(w_2\) | \(w_3\) | \(y_1\) | \(y_2\) | \(y_3\) | |
|---|---|---|---|---|---|---|---|
| Base Case w/o Setup | 8845 | 0 | 307 | 231 | 0 | 0 | 0 |
| Base Case with Setup | 5345 | 0 | 307 | 231 | 0 | 0 | 0 |
| Optimal Fixed Charge | 6500 | 500 | 0 | 0 | 1 | 0 | 0 |
Notice that the the high setup costs have caused us to focus our production planning decisions. Rather than spreading ourselves across three different product lines, we are producing as many of widget 1 as we can.
6.7 Model Results and Interpretation
We can also calculate our resource usage.
fc_bigM_res.W1 <- get_solution(fc_bigM_res, Vw1)
# Extract solution value for decision variable, W1
fc_bigM_res.W2 <- get_solution(fc_bigM_res, Vw2)
# Extract solution value for decision variable, W2
fc_bigM_res.W3 <- get_solution(fc_bigM_res, Vw3)
# Extract solution value for decision variable, W3
fc_bigM_res.df <- data.frame(c(fc_bigM_res.W1,
fc_bigM_res.W2,
fc_bigM_res.W3))
fc_bigM_res.r1 <- t(data.frame(c(fc_bigM_res.W1*2,
fc_bigM_res.W2*1,
fc_bigM_res.W3*3)))
#multiply results with hours used
rownames(fc_bigM_res.r1) <- "Pre-process"
fc_bigM_res.r2 <- t(data.frame(c(fc_bigM_res.W1*1,
fc_bigM_res.W2*5,
fc_bigM_res.W3*2)))
#multiply results with hours used
rownames(fc_bigM_res.r2) <- "Machining"
fc_bigM_res.r3 <- t(data.frame(c(fc_bigM_res.W1*2,
fc_bigM_res.W2*1,
fc_bigM_res.W3*1)))
#multiply results with hours used
rownames(fc_bigM_res.r3) <- "Assembly"
fc_bigM_res.r4 <- t(data.frame(c(fc_bigM_res.W1*3,
fc_bigM_res.W2*2,
fc_bigM_res.W3*1)))
#multiply results with hours used
rownames(fc_bigM_res.r4) <- "Quality Assurance"
fc_bigM_res.tot <- data.frame(c(sum(fc_bigM_res.r1),
sum(fc_bigM_res.r2),
sum(fc_bigM_res.r3),
sum(fc_bigM_res.r4)))
#sum each step
colnames(fc_bigM_res.tot) <- "Total Used"
fc_bigM_res.avail <- data.frame(
c("1000","2000","1000","1500"))
#print available hours for each step
colnames(fc_bigM_res.avail) <- "Available"
Res_Usage <- cbind(fc_bigM_res.tot, fc_bigM_res.avail)
rownames(Res_Usage)<-c("Pre-process", "Machining",
"Assembly", "Quality Assurance")
kbl (cbind(Res_Usage),
booktabs=T, caption =
"Manufacturing Resource Usage") |>
kable_styling(latex_options = "hold_position")| Total Used | Available | |
|---|---|---|
| Pre-process | 1000 | 1000 |
| Machining | 500 | 2000 |
| Assembly | 1000 | 1000 |
| Quality Assurance | 1500 | 1500 |
As can be seen, we used all of our Pre-processing hours, Assembly hours, and Quality Assurance hours. There is a significant amount of time available in Machining though.
Further analysis could examine alternatives such as redesigning widget 2 and 3 to be less resource intensive in production to see at what point we would choose to produce them.
Exercise 6.8 (Redesign Widget 3) The design team has an idea of how to use a previous manufacturing fixture which could eliminate the setup cost for Widget 3. How much would you produce of Widget 3 if there were no setup (fixed) cost for production of Widget 3? Of course this still keeps a cost for Widgets 1 and 2. Experiment with the above model to find the lowest setup cost for Widget 3 where you still choose to not produce any of Widget 3.
Exercise 6.9 (Reducing Fixed Costs) How would production change if the setup costs were cut in half due to implementing lean production approaches?
Exercise 6.10 (Adding a Fourth Widget) Consider adding a new widget 4 which needs 4, 3, 2, and 5 hours for Pre-processing, Machining, Assembly, and Quality Assurance respectively. Widget 4 uses the same setup as Widget 3 which means no repeated setup cost for Widget 4 if widget 3 is already being produced.
Solve the model to obtain the production plan where both Widget 3 and Widget 4 are produced.
This example is based on an example from Thanh Thuy Nguyen.↩︎